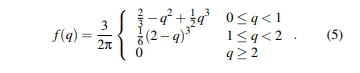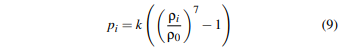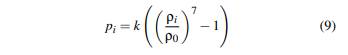SPH 탄생 배경
SPH의 탄생 배경은 SPH(Smoothed Particle Hydrodynamics)의 시초로 꼽히는 논문( Gingold & Monaghan 1977)에 잘 나와있습니다.
SPH는 1977년경 천문학 및 우주론 분야에서 처음 제안되었습니다.
당시 사용되던 오일러 방식(Eulerian)의 격자 기반 수치 해석 기법은, 고정된 격자(공간의 한 지점)를 기준으로 유체의 물리량 변화를 관찰하는 방식인데, 3차원 문제의 경우 격자 밀도가 급격히 증가하여 계산량이 기하급수적으로 늘어나 시뮬레이션하기 어려웠습니다.
이에 반해, 라그랑지안 방식(Lagrangian)은 유체를 구성하는 개별 입자 혹은 물질 덩어리를 따라가며 그 변화를 추적하는 방식으로, 자유 표면이나 큰 변형을 자연스럽게 처리할 수 있으면서 계산량을 줄일 수 있다는 장점이 있었습니다.
따라서, SPH는 계산 효율성을 크게 개선하고 복잡한 천체 물리 문제를 다루기 위해 이 라그랑지안 방식을 도입한 것입니다
그러면 Smoothing 함수가 무엇인가?
여기서의 스무딩 함수는 SPH에서는 각 입자가 고유의 질량, 밀도, 속도 등의 값을 갖고 있지만, 해당 값들이 하나의 점에 국한되지 않고, "주변 영역에 걸쳐 영향을 미치도록" 하기위해서 Smoothing 함수 정의하여 사용한다.
이 Smoothing 함수를 Kernel(커널) 함수라고 부르고, 이 함수는 보통 입자 사이의 거리와 Smoothing(평활화) 반경(h)에 따라서 가중치를 부여하고, 하나의 입자에 의한 물리량을 주변으로 "환산"시켜 마치 블러 효과를 주듯이, 마치 하나의 점의 영향력을 표현하자면, 하나의 점이 주변으로 스무딩되듯 부드럽게 연결한다.

위 사진은 커널 함수의 원리에 대한 사진이다. 한 입자에서 이웃 입자 사이의 거리와 평활화 반경(h) 매개변수로 kernel 입자에 전달해주게 되면, 얼마만큼의 가중치가 발생하는지를 알수있다.
여러 SPH Kernel Function 소개 : https://interactivecomputergraphics.github.io/physics-simulation/examples/sph_kernel.html
그렇다면 이 커널 함수의 결과를 어디에 사용하는가?
직전에 말했듯, 커널 함수를 통해서 한 입자와 다른 입자 사이의 거리와 평활화 반경을 통해서 얼마만큼의 영향력이 발생하는지를 알수있다고 했다.
그렇다면 평활화 반경을 통해 한 입자에서 평활화 반경 내에 있는 모든 입자들까지의 영향력을 알아낼수있다.
즉, 한 입자에서 평활화 반경 내에 존재하는 입자들과의 영향력의 총합을 통해, 해당 입자의 물리적 특성을 근사할수있다.
그렇게 해서 근사해낸 영향력으로 한 입자의 밀도를 구하고, 밀도로 압력을 구하고, 압력으로 힘을 구해서, 해당 입자가 다음 타임 스텝에 어느 방향으로 움직여야하는지를 근사해, 다음 위치를 계산하는 것이다.
그럼 먼저 사용할 커널 함수 방정식을 세운다.
 |
  |
평활화 반경(h)와 입자 사이의 거리(x)의 차에 세제곱(음수가 될수있으니 미리 0이상으로 설정)을 하면, 왼쪽 사진의 커널 그래프 모습과 비슷하게 오른쪽과 같이 나온다.
그런데 이 식을 그대로 쓰면안되고, 위 식을 통해서 나오는 값은 영향력 분포 형태를 정의하는것이다.
이걸 단위부피당 값으로 표현해서, 전체 부피를 1로 만들어야하기때문에 해당 위치에서의 부피로 나눠줘야한다.

그래서 위 적분식의 결과를 통해서 오른쪽의 식으로 부피를 구한다음 이걸로 나눠준 결과를 최종 영향력으로 사용하면된다.
이렇게 커널 함수를 설정하고, 이 결과 값을 가중치로 사용한다.

위는 입자를 64 x 64로 배치한 모습이다.
그렇다면 일반적으로 이 상황에서 "한 입자"에서 "평활화 반경 내의 밀도"는 어떻게 측정되어야할까?
모든 입자들이 동일한 간격으로 배치되어있으니, 반경 내에 입자들의 간격이 동일하다면, 입자 배치의 중심에서 평활화 반경을 증가시키거나 줄였을때, 측정되는 밀도는 항상 동일할것이다.
 |
 |
왼쪽은 평활화 반경이 1일때이고, 오른쪽은 3일때 측정한것인데, 수치가 비슷하지만 오차가 발생하는 이유는 부동소수점 연산때문에 그렇다.
 |
 |
위처럼 특정 평활화 반경에서 그 주변 입자의 몇몇 입자들과 밀도를 비교해서 거의 같으면된다
밀도 구하기

어떤 입자의 물리량을 다른 입자들과의 연관성을 통해서 알고싶을때 위 보간식을 사용해서 계산할수있다.
위 식은 위치 x에서의 물리량 A(x) 는 주변 입자 i 들의 물리량 A_i에 각 입자의 크기(부피)와 위치 x에 대한 영향력(커널 함수)를 곱한 값들을 모두 더해서 얻어진다. 라는 의미이다.
그랬을때, A_i가 밀도라고 하면, 이미 밀도로 나눠주기때문에 상쇄되어 사라지게된다.

그럼 최종적으로 밀도를 구하는 식은 위와 같다.
출처
https://www.youtube.com/watch?v=rSKMYc1CQHE&t=287s&ab_channel=SebastianLague
https://interactivecomputergraphics.github.io/physics-simulation/examples/sph_kernel.html
https://matthias-research.github.io/pages/publications/sca03.pdf
'SPH' 카테고리의 다른 글
| SPH 개발 현황 (0) | 2025.04.09 |
|---|---|
| SPH 시뮬레이션 안정화 (0) | 2025.04.09 |
| 파티클 시스템 결과 렌더링 (0) | 2025.04.04 |
| 파티클 시스템 (0) | 2025.04.03 |
| SPH Fluids in Computer Graphics 1장 흐름 정리 (0) | 2025.04.03 |